Abstract
To deliver coherent and personalized experiences in long-term conversations, existing approaches typically perform retrieval augmented response generation by constructing memory banks from conversation history at either the turn-level, session-level, or through summarization. In this paper, we present two key findings: (1) The granularity of memory unit matters: Turn-level, session-level, and summarization-based methods each exhibit limitations in both memory retrieval accuracy and the semantic quality of the retrieved content. (2) Prompt compression methods, such as LLMLingua-2, can effectively serve as a denoising mechanism, enhancing memory retrieval accuracy across different granularities. Building on these insights, we propose SeCom, a method that constructs the memory bank at segment level by introducing a conversation Segmentation model that partitions long-term conversations into topically coherent segments, while applying Compression based denoising on memory units to enhance memory retrieval. Experimental results show that SeCom exhibits a significant performance advantage over baselines on long-term conversation benchmarks LOCOMO and Long-MT-Bench+. Additionally, the proposed conversation segmentation method demonstrates superior performance on dialogue segmentation datasets such as DialSeg711, TIAGE, and SuperDialSeg.
Key Takeaways
✅ Memory granularity matters: Turn-level, session-level & summarization-based memory struggle with retrieval accuracy and the semantic integrity or relevance of the context.
✅ Prompt compression methods (e.g., LLMLingua-2) can denoise memory retrieval, boosting both retrieval accuracy and response quality.
What's the Impact of Memory Granularity?
We first systematically investigate the impact of different memory granularities on conversational agents within the paradigm of retrieval augmented response generation. Our findings indicate that turn-level, session-level, and summarization-based methods all exhibit limitations in terms of the accuracy of the retrieval module as well as the semantics of the retrieved content, which ultimately lead to sub-optimal responses.
💡 Long conversations are naturally composed of coherent discourse units. To capture this structure, we introduce a conversation segmentation model that partitions long-term conversations into topically coherent segments, constructing the memory bank at the segment level. During response generation, we directly concatenate the retrieved segment-level memory units as the context, bypassing summarization to avoid the information loss that often occurs when converting dialogues into summaries.
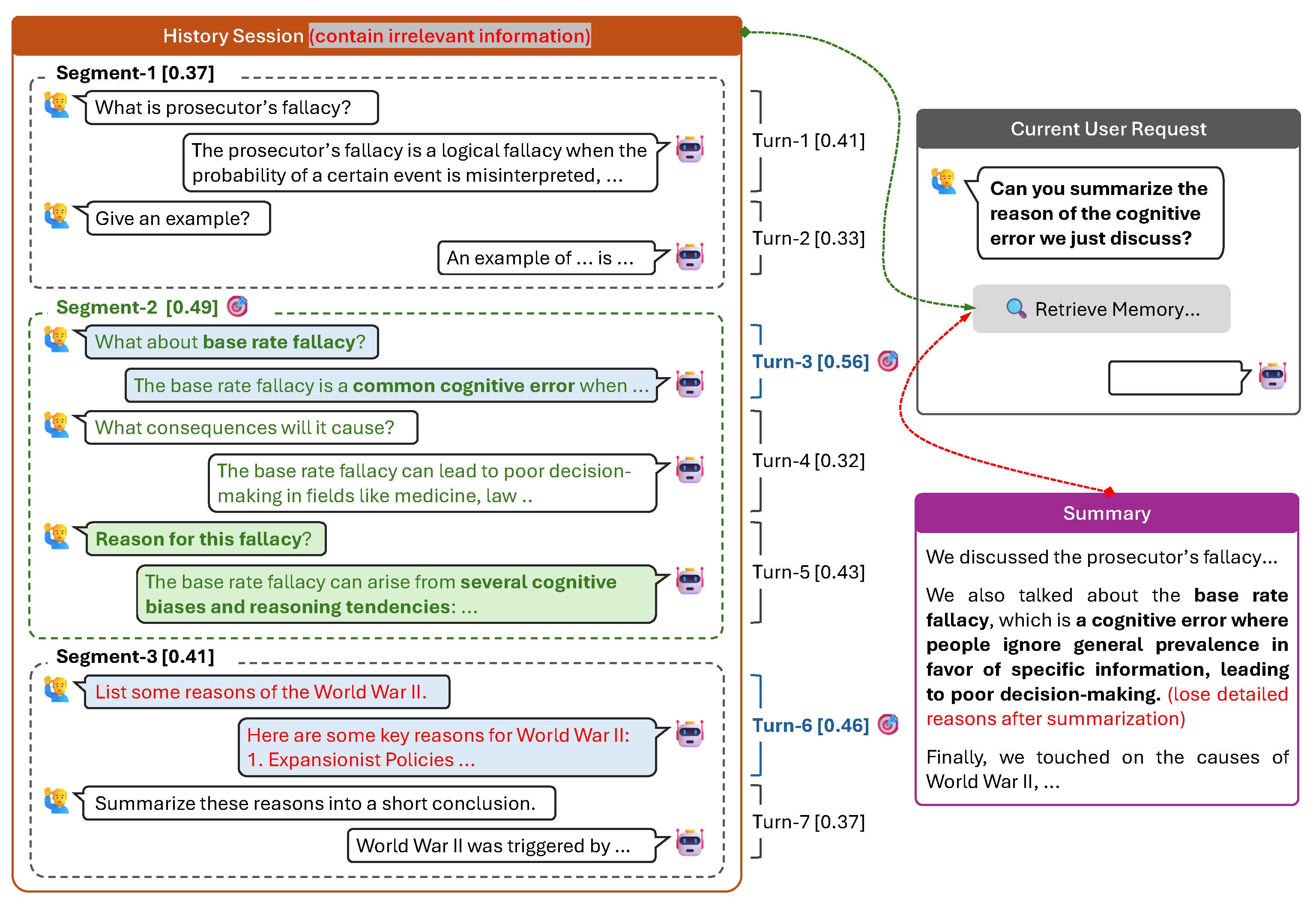
Figure 1. Illustration of retrieval augmented response generation with different memory granularities. Turn-level memory is too fine-grained, leading to fragmentary and incomplete context. Session-level memory is too coarse-grained, containing too much irrelevant information. Summary based methods suffer from information loss that occurs during summarization. Ours (segment-level memory) can better capture topically coherent units in long conversations, striking a balance between including more relevant, coherent information while excluding irrelevant content. 🎯 indicates the retrieved memory units at turn level or segment level under the same context budget. [0.xx]: similarity between target query and history content. Turn-level retrieval error: false negative, false positive.
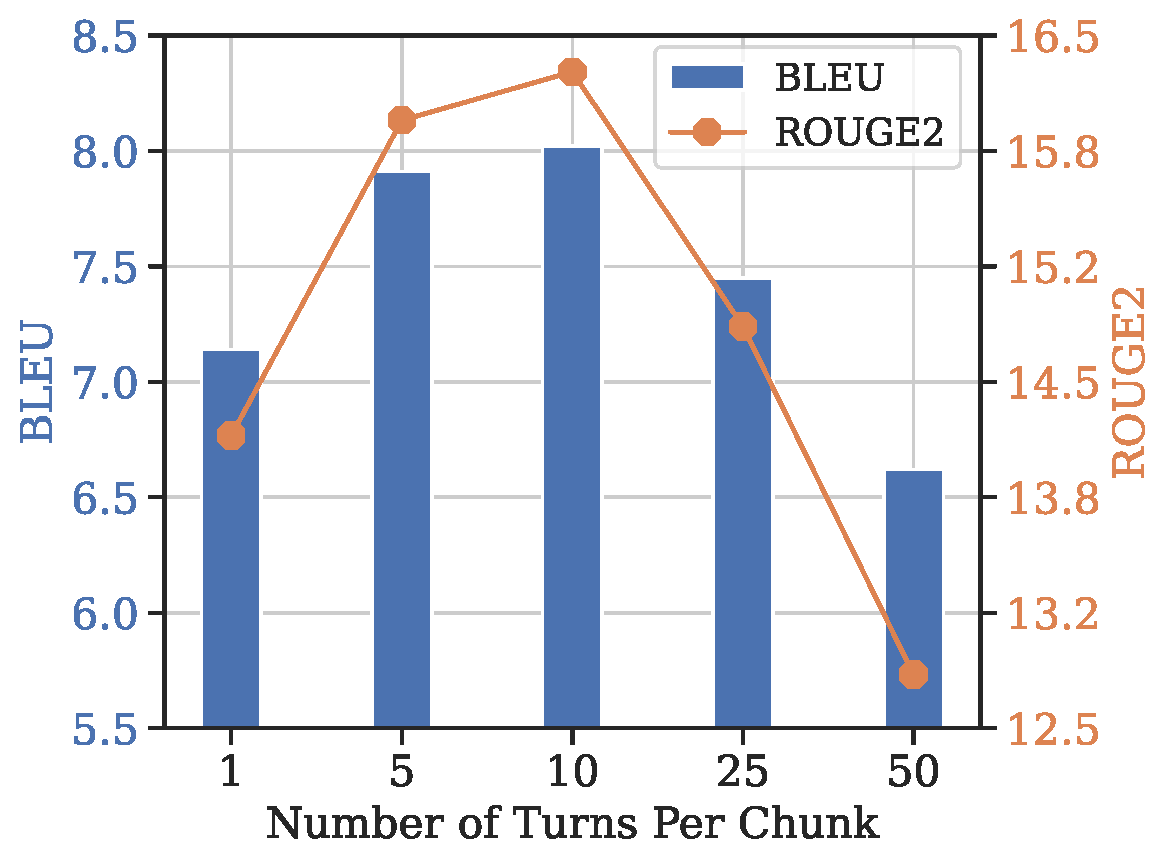
(a) Response quality as a function of chunk size, given a total budget of 50 turns to retrieve as context.
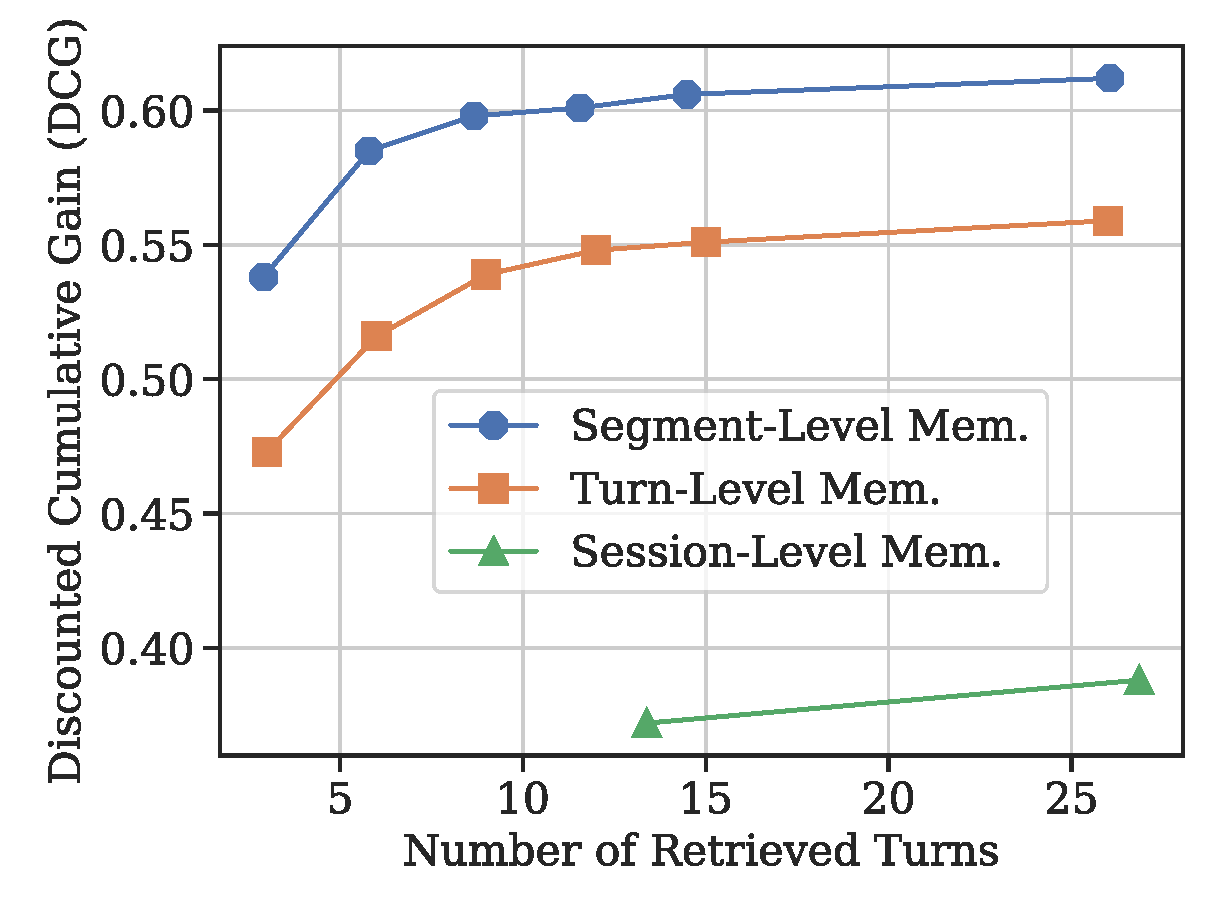
(b) Retrieval DCG obtained with different memory granularities using BM25-based retriever.
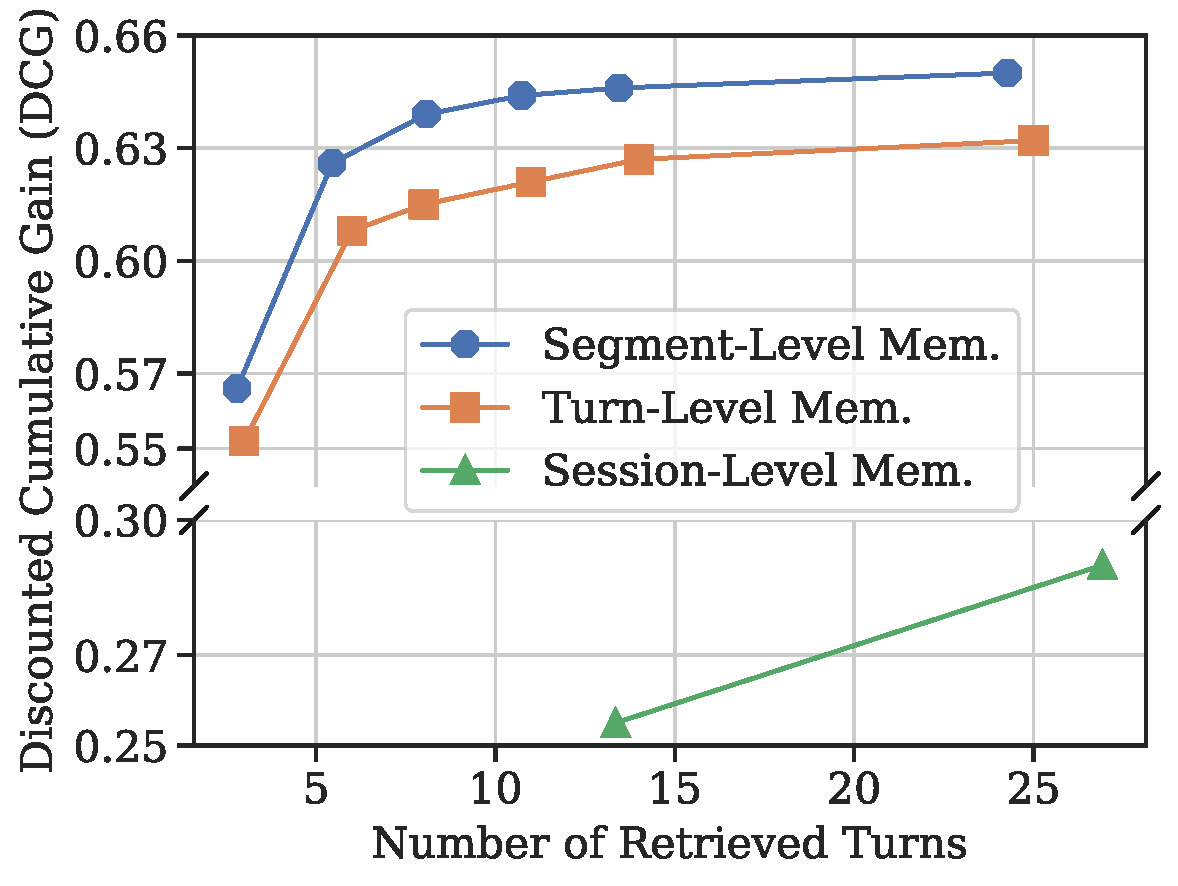
(c) Retrieval DCG obtained with different memory granularities using MPNet-based retriever.
Figure 2. How memory granularity affects (a) the response quality and (b, c) retrieval accuracy.
Does Memory Denoising Help?
Inspired by the notion that natural language tends to be inherently redundant, we hypothesize that such redundancy can act as noise for retrieval systems, complicating the extraction of key information. Therefore, we propose removing such redundancy from memory units prior to retrieval by leveraging prompt compression methods such as LLMLingua-2. Figure 3 shows the results.
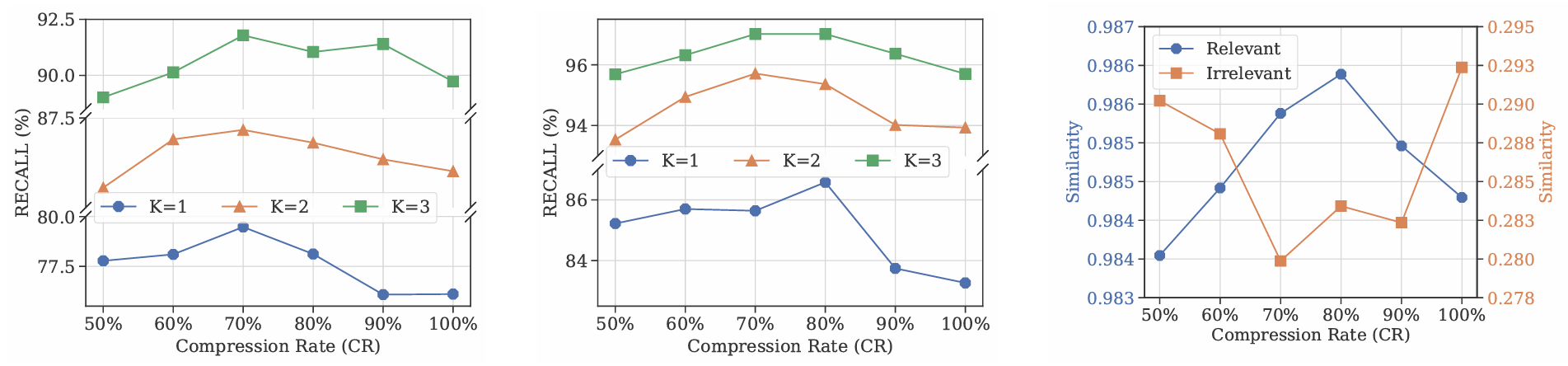
(a) Retrieval recall v.s. compression rate: $\frac{\text{#tokens after compression}}{\text{#tokens before compression}}$. K: number of retrieved segments. Retriever: BM25.
(b) Retrieval recall v.s. compression rate: $\frac{\text{#tokens after compression}}{\text{#tokens before compression}}$. K: number of retrieved segments. Retriever: MPNet.
(c) Similarity between the query and different dialogue segments. Blue: relevant segments. Orange: irrelevant segments. Retriever: MPNet.
Figure 3. Prompt compression method (LLMLingua-2) can serve as an effective denoising technique to enhance the memory retrieval system by: (a) improving the retrieval recall with varying context budget K; (b) benefiting the retrieval system by increasing the similarity between the query and relevant segments while decreasing the similarity with irrelevant ones.
SeCom
To address the above challenges, we present SeCom, a system that constructs memory bank at segment level by introducing a Conversation Segmentation Model, while applying Compression-Based Denoising on memory units to enhance memory retrieval.
Conversation Segmentation Model
Given a conversation session $\mathbf{c}$, the conversation segmentation model $f_{\mathcal{I}}$ aims to identify a set of segment indices $\mathcal{I}=\{(p_{k}, q_{k})\}_{k=1}^{K}$, where $K$ denotes the total number of segments within the session $\mathbf{c}$, $p_{k}$ and $q_{k}$ represent the indexes of the first and last interaction turns for the $k$-th segment $\mathbf{s}_{k}$, with $p_{k} \leq q_{k}$, $p_{k+1} = q_k + 1$. This can be formulated as: $$ f_{\mathcal{I}}(\mathbf{c}) = \{\mathbf{s}_k\}_{k=1}^K, \\ \text{where}~\mathbf{s}_k =\{\mathbf{t}_{p_k}, \mathbf{t}_{p_k+1}, ..., \mathbf{t}_{q_k}\}. $$ We employ GPT-4 as the conversation segmentation model $f_{\mathcal{I}}$. We find that more lightweight models, such as Mistral-7B and even RoBERTa scale models, can also perform segmention well, making our approach applicable in resource-constrained environments.
Compression-Based Memory Denoising
Given a target user request $u^*$ and context budget $N$, the memory retrieval system $f_R$ retrieves $N$ memory units $\{\mathbf{m}_n\in\mathcal{M}\}_{n=1}^N$ from the memory bank $\mathcal{M}$ as the context in response to the user request $u^*$. With the consideration that the inherent redundancy in natural language can act as noise for the retrieval system, we denoise memory units by removing such redundancy via a prompt compression model $f_{Comp}$ before retrieval: $$ \{\mathbf{m}_n\in\mathcal{M}\}_{n=1}^N \leftarrow f_R(u^*, f_{Comp}(\mathcal{M}), N). $$
Experiment
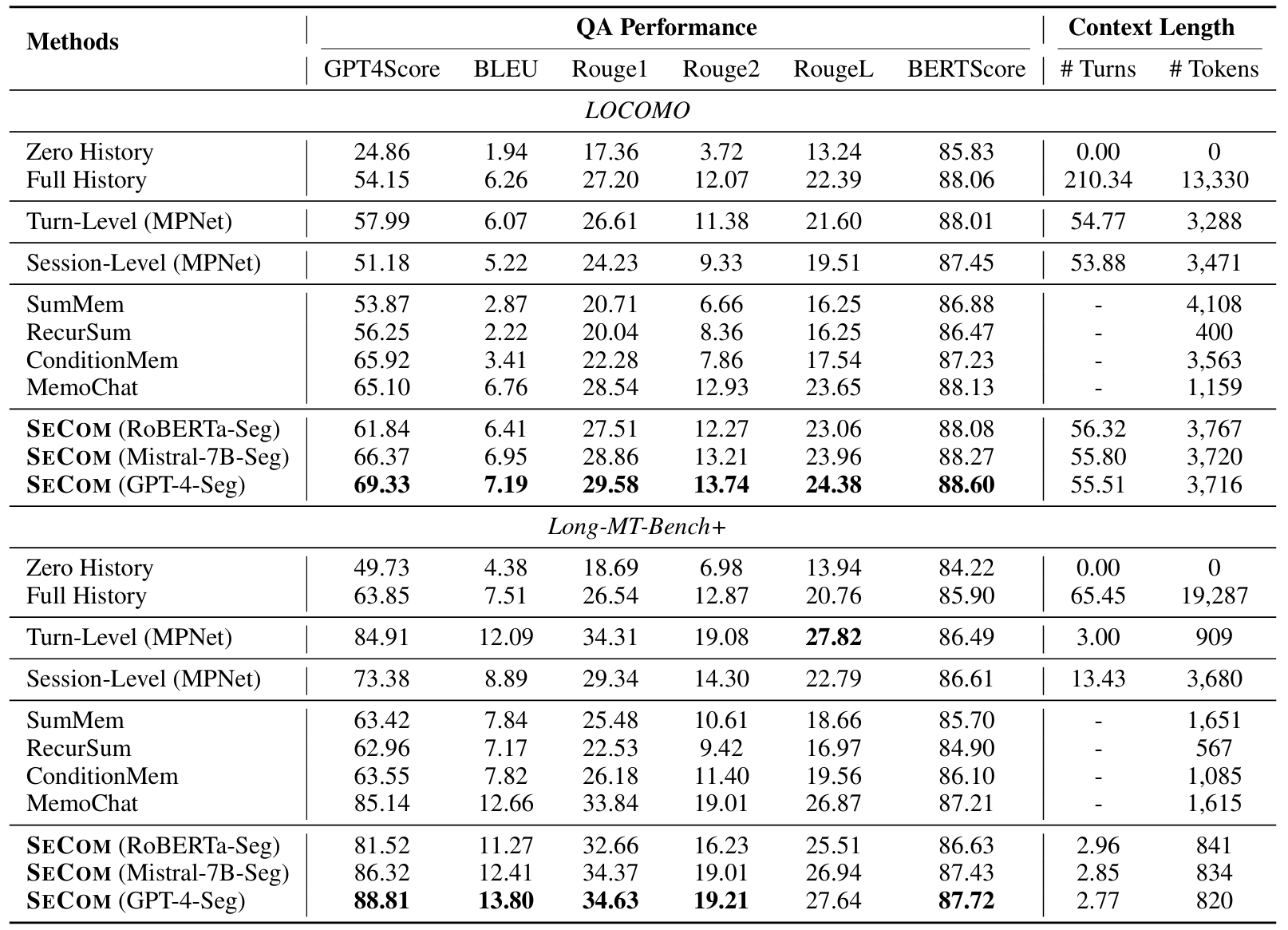
We evaluate SeCom against four intuitive approaches and four state-of-the-art models on long-term conversation benchmarks: LOCOMO and Long-MT-Bench+.
Main Result
-
As shown in the following table, SeCom outperforms all baseline approaches, exhibiting a significant performance advantage, particularly on the long-conversation benchmark LOCOMO. Interestingly, there is a significant performance disparity in turn-Level and session-Level methods when using different retrieval models. In contrast, SeCom enjoys greater robustness in terms of the deployed retrieval system.
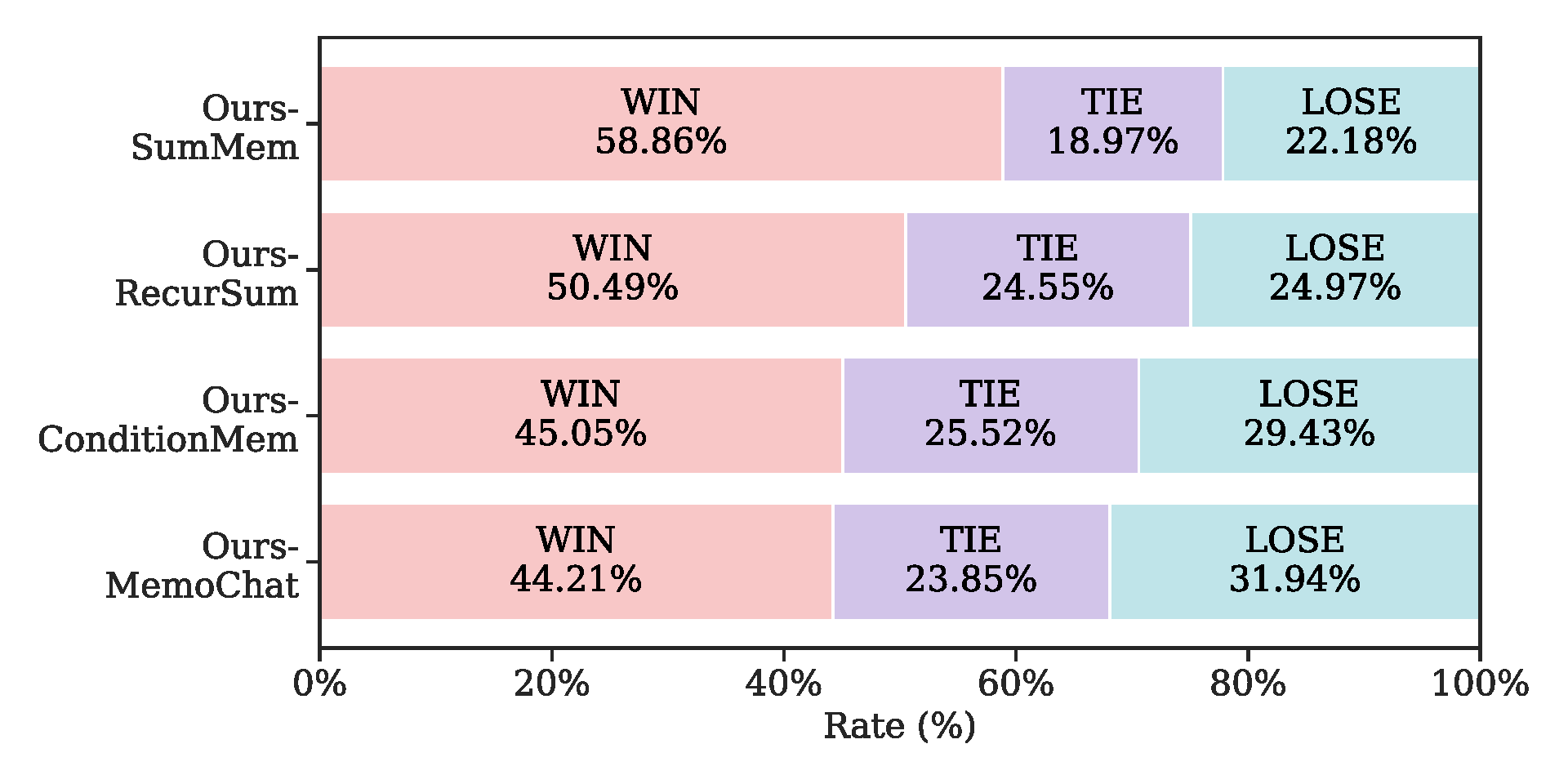
The figure below presents the pairwise comparison result by instructing GPT-4 to determine the superior response. SeCom achieves a higher win rate compared to all baseline methods. We attribute this to the fact that topical segments in SeCom can strike a balance between including more relevant, coherent information while excluding irrelevant content, thus leading to more robust and superior retrieval performance.
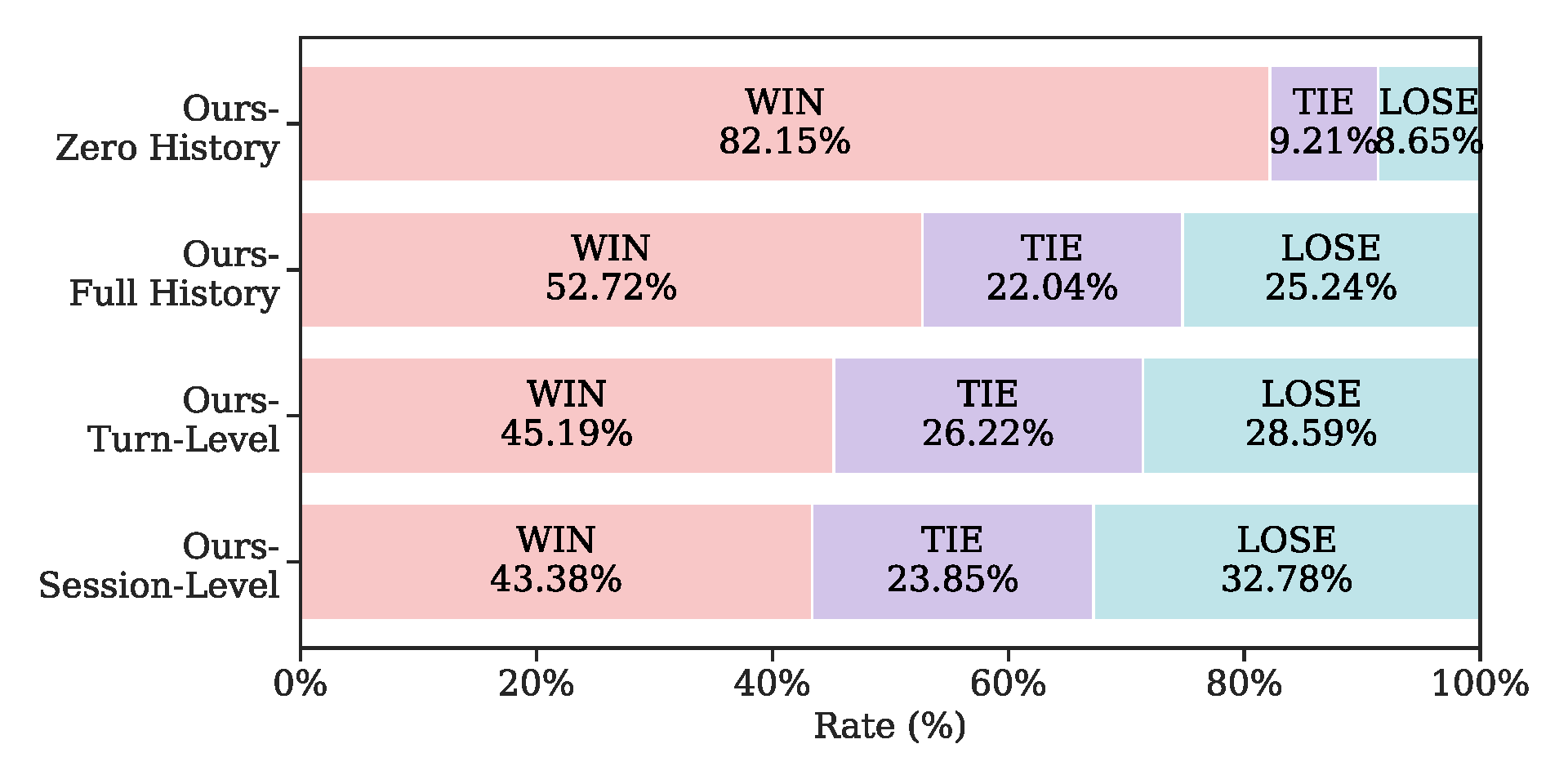
Impact of the Memory Unit Granularity
-
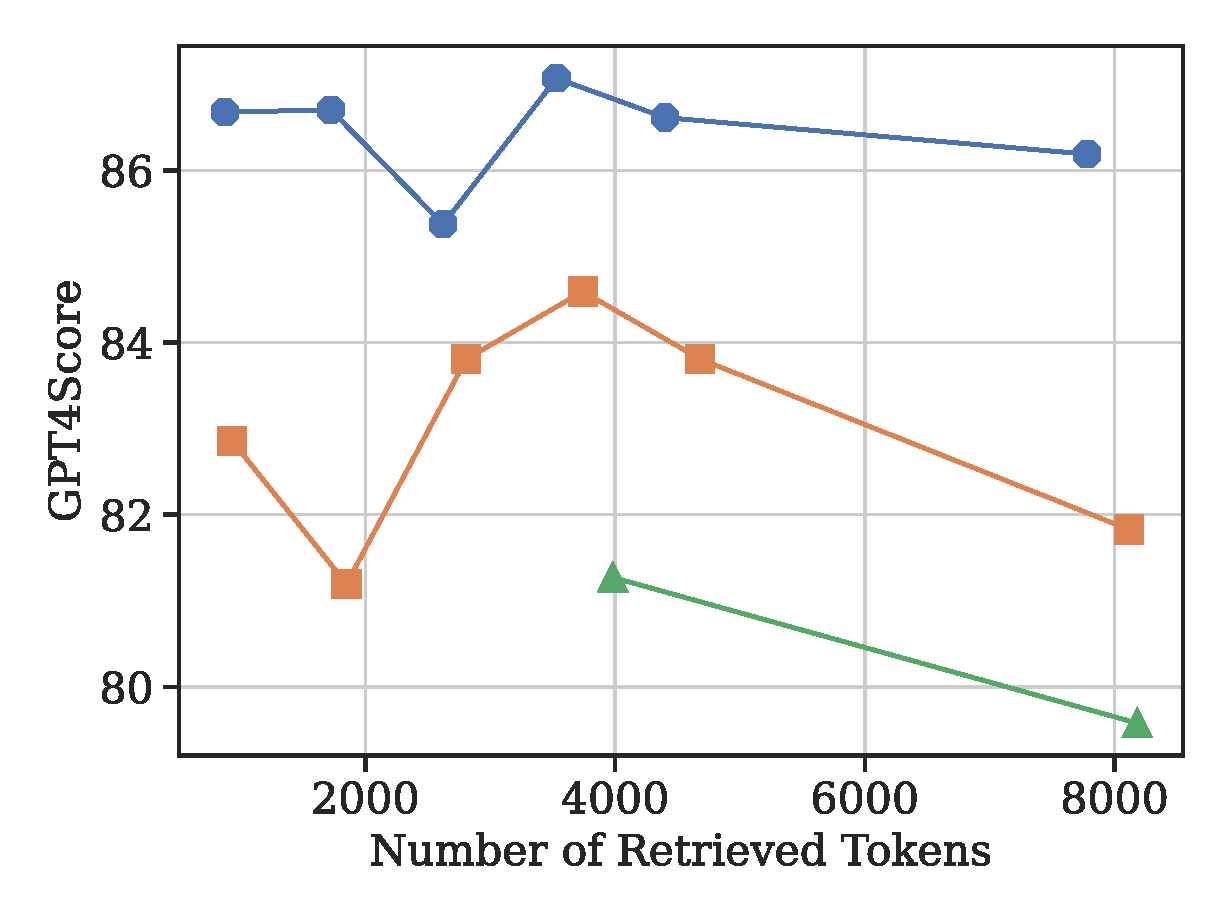
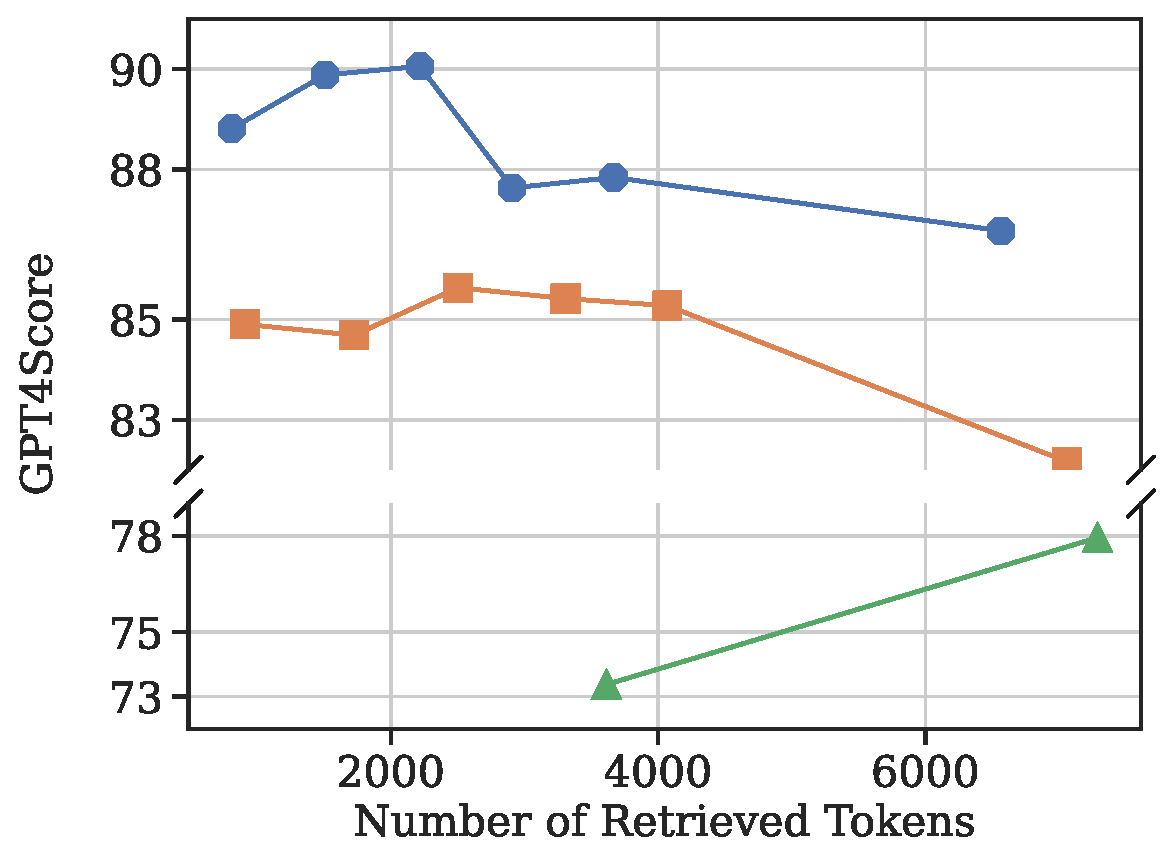
The figure below compares QA performance across different memory granularities under varying context budgets, demonstrating the superiority of segment-level memory over turn-level and session-level memory.
Evaluation of Conversation Segmentation Model
-
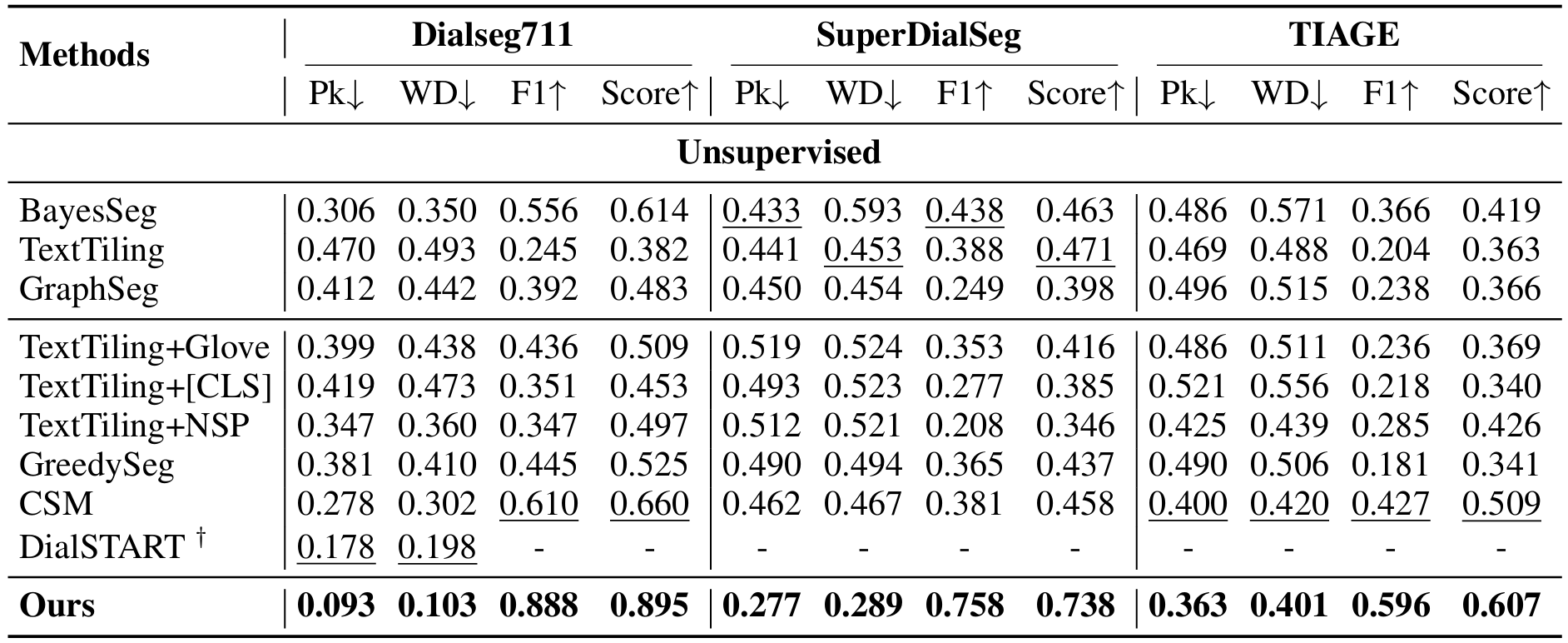
We evaluate the conversation segmentation module independently on widely used dialogue segmentation datasets: DialSeg711, TIAGE and SuperDialSeg.
The following table presents the result, showing that our segmentation model consistently outperforms baselines in the unsupervised segmentation setting.
The Effect of Compression-Based Memory Denoising
-
As shown in table below, removing the proposed compression-based memory denoising mechanism will result in a performance drop up to 9.46 points of GPT4Score on LOCOMO, highlighting the critical role of this denoising mechanism: by effectively improving the retrieval system, it significantly enhances the overall effectiveness of the system.

BibTeX
@inproceedings{pan2025secom,
title={SeCom: On Memory Construction and Retrieval for Personalized Conversational Agents},
author={Zhuoshi Pan and Qianhui Wu and Huiqiang Jiang and Xufang Luo and Hao Cheng and Dongsheng Li and Yuqing Yang and Chin-Yew Lin and H. Vicky Zhao and Lili Qiu and Jianfeng Gao},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=xKDZAW0He3}
}