Abstract
In long context scenarios, large language models face three main challenges: higher computational cost, performance reduction, and position bias. Research indicates that LLM performance hinges on the density and position of key information in the input prompt. Inspired by these findings, we propose LongLLMLingua for prompt compression towards improving LLMs’ perception of the key information to simultaneously address the three challenges. Our extensive evaluation across various long context scenarios demonstrates that LongLLMLingua not only enhances performance but also significantly reduces costs and latency. For instance, in the NaturalQuestions benchmark, LongLLMLingua boosts performance by up to 21.4% with around 4x fewer tokens in GPT-3.5-Turbo, leading to substantial cost savings. It achieves a 94.0% cost reduction in the LooGLE benchmark. Moreover, when compressing prompts of about 10k tokens at ratios of 2x-6x, LongLLMLingua can accelerate end-to-end latency by 1.4x-2.6x.
Insights
Natural language is redundant, amount of information varies.
LLMs can understand compressed prompt.
There is a trade-off between language completeness and compression ratio. (LLMLingua)
GPT-4 can recover all the key information from a compressed prompt-emergent ability. (LLMLingua)
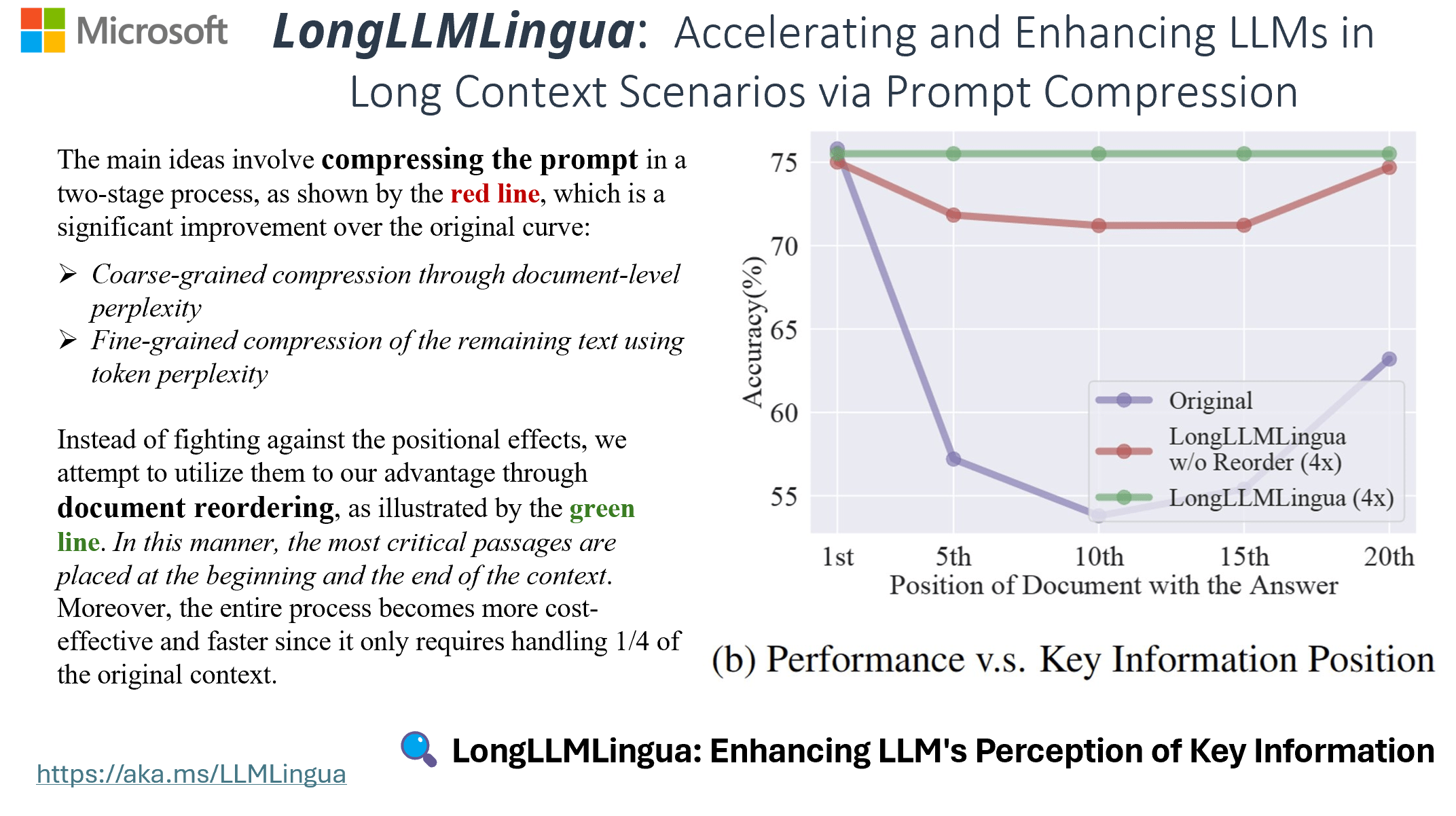
The density and position of key information in a prompt affect the performance of downstream tasks. (LongLLMLingua)
For more details, please refer to the paper LongLLMLingua.
Why LongLLMLingua?
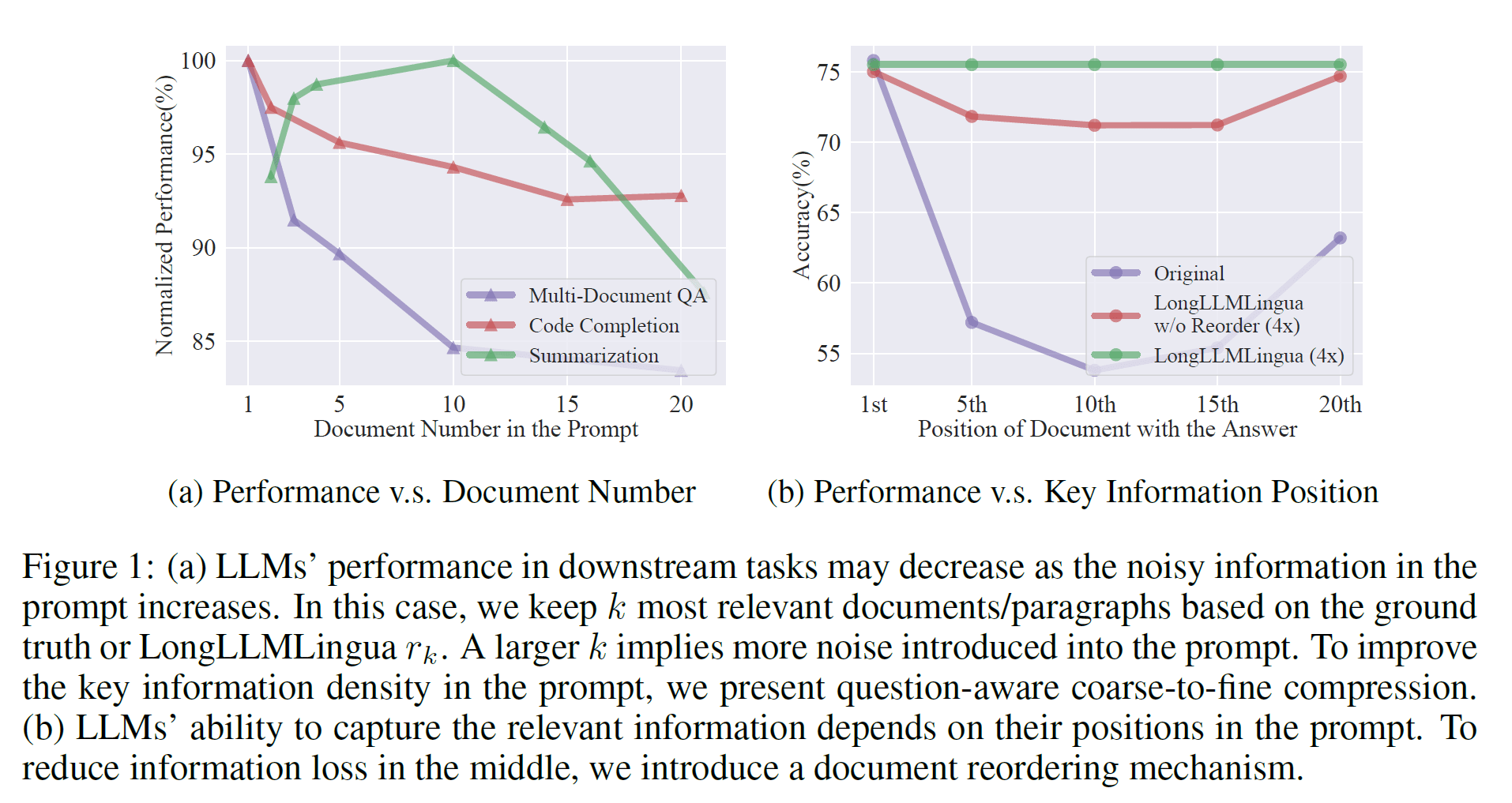
In long context scenarios, the distribution of key information is generally very sparse. Previous work has found that the density and placement of relevant information significantly impact the performance of Large Language Models (LLMs), even for highly powerful models like GPT-4-Turbo. LongLLMLingua capitalizes on these distribution characteristics by employing prompt compression and reorganization. This strategy schedules and utilizes the limited but powerful context windows for LLMs more efficiently, effectively mitigating the "Lost in the middle" issue. As illustrated in the figure above, LongLLMLingua can achieve up to a 21.4% improvement on the NQ Multi-document QA task while using only 1/4 of the tokens.
Our main contributions are five-fold:
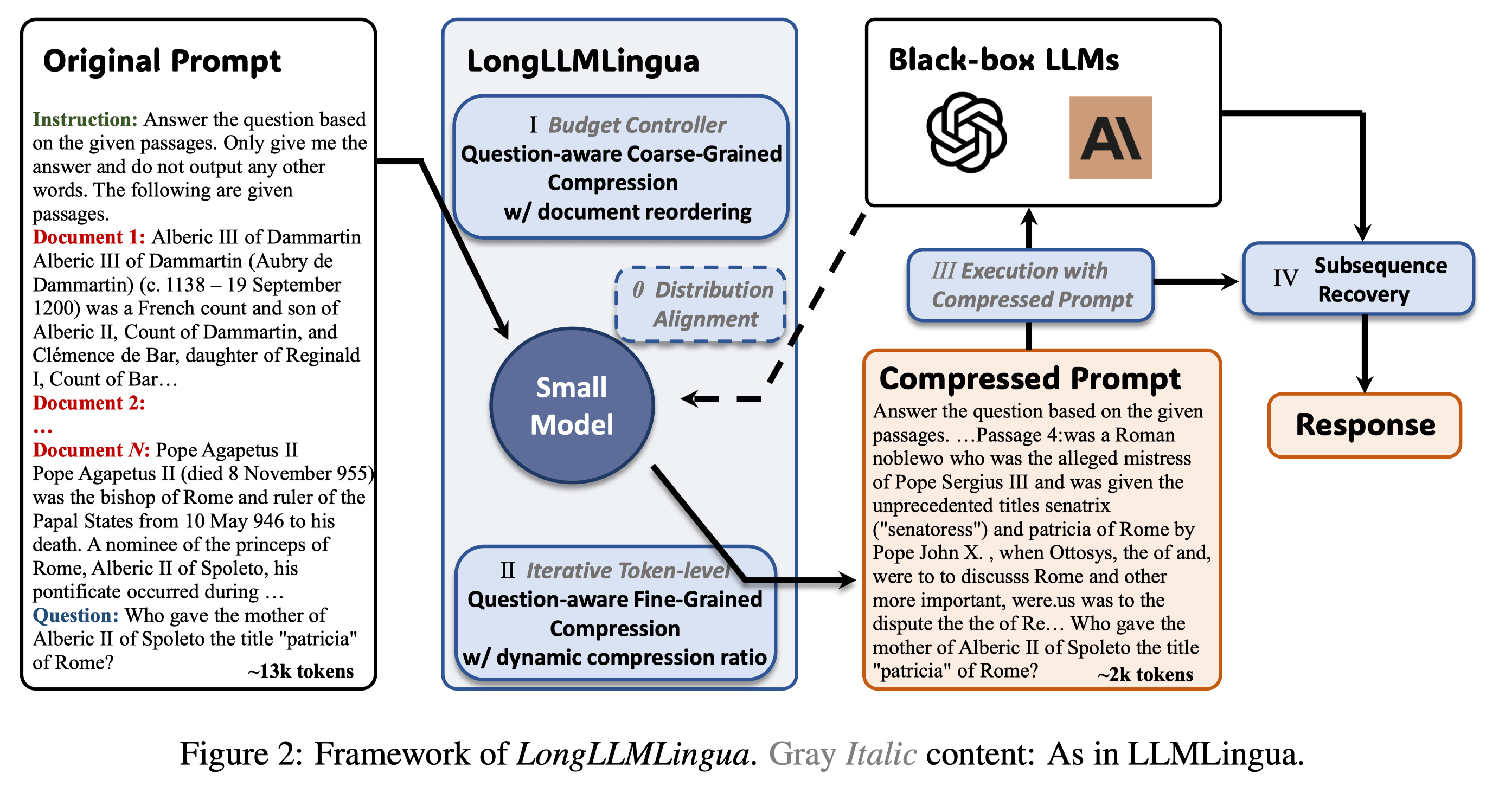
We propose a question-aware coarse-to-fine compression method to improve the key information density in the prompt.
We introduce a document reordering strategy to minimize position bias in LLMs.
We establish dynamic compression ratios for precise control between coarse and fine compression levels
We propose a post-compression subsequence recovery strategy to improve the integrity of the key information
We evaluate LongLLMLingua across five benchmarks, i.e., NaturalQuestions, LongBench, ZeroSCROLLS , MuSicQue, and LooGLE, covering a variety of long context scenarios. Experimental results reveal that LongLLMLingua’s compressed prompts outperform original prompts in terms of performance, cost efficiency, and system latency.
Empirical Studies of Question-aware Compression
To test the effectiveness of our proposed question-aware coarse-grained and fine-grained compression method, we conducted an empirical study across two dimensions.
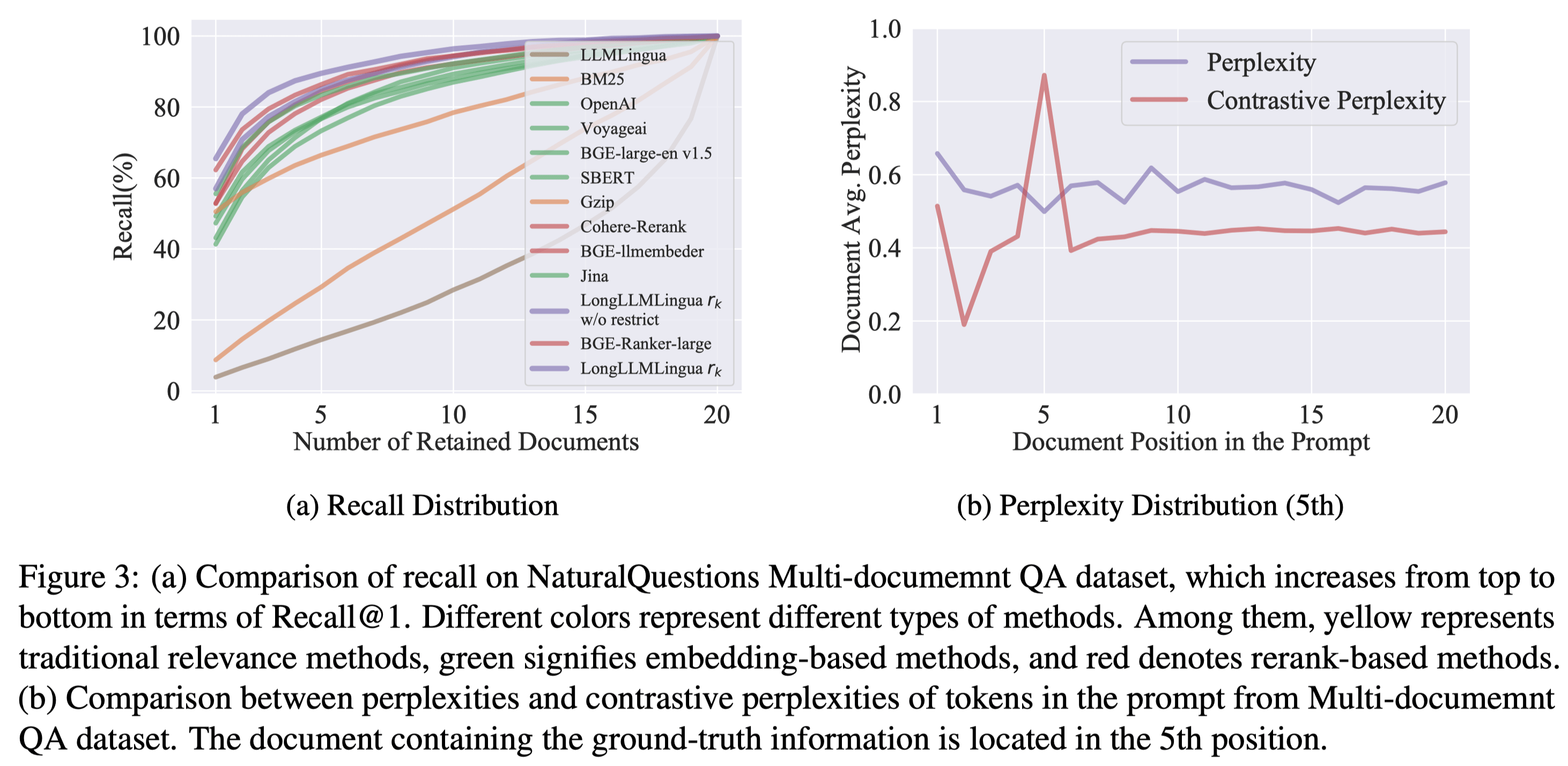
Firstly, we analyzed the effectiveness of the question-aware coarse-grained approach by comparing it with several state-of-the-art (SoTA) retrieval methods in real Retrieval-Augmented Generation (RAG) scenarios. We discovered that our method not only surpasses traditional retrieval methods such as BM25 and Gzip but also outperforms embedding methods like OpenAI embedding, Jina, and BGE, as well as various reranker methods, including Cohere reranker and BGE-Reranker.
Secondly, we assessed the effectiveness of the question-aware fine-grained approach by comparing perplexity and contrastive perplexity across various document context scenarios. It was observed that contrastive perplexity effectively captures key information in documents, while perplexity struggles to identify relevant information.
Experiments Results in RAG scenarios (Multi-document QA)
We tested LLMLingua across a range of scenarios, such as multi-document QA, coding, retrieval-based tasks, multi-hop QA, summarization, and ranking, with the NQ multi-document QA results highlighted below. Notably, LongLLMLingua effectively mitigates the 'lost in the middle' issue, achieving up to a 21.4% improvement at 4x compression and achieving a 2.1x acceleration in end-to-end latency.
| Methods | 1st | 5th | 10th | 15th | 20th | Reorder | Tokens | 1/𝜏 | Speedup |
|---|---|---|---|---|---|---|---|---|---|
| BM25 | 40.6 | 38.6 | 38.2 | 37.4 | 36.6 | 36.3 | 798 | 3.7x | 1.5 (2.7x) |
| Gzip | 63.1 | 61.0 | 59.8 | 61.1 | 60.1 | 62.3 | 824 | 3.6x | 1.5 (2.7x) |
| SBERT | 66.9 | 61.1 | 59.0 | 61.2 | 60.3 | 64.4 | 808 | 3.6x | 1.6 (2.5x) |
| OpenAI | 63.8 | 64.6 | 65.4 | 64.1 | 63.7 | 63.7 | 804 | 3.7x | 4.3 (1.0x) |
| LongLLMlingua rk | 71.1 | 70.7 | 69.3 | 68.7 | 68.5 | 71.5 | 807 | 3.7x | 1.7 (2.4x) |
| Selective-Context | 31.4 | 19.5 | 24.7 | 24.1 | 43.8 | - | 791 | 3.7x | 6.8 (0.6x) |
| LLMLingua | 25.5 | 27.5 | 23.5 | 26.5 | 30.0 | 27.0 | 775 | 3.8x | 1.8 (2.2x) |
| LongLLMLingua | 75.0 | 71.8 | 71.2 | 71.2 | 74.7 | 75.5 | 748 | 3.9x | 2.1 (2.0x) |
| Original Prompt | 75.7 | 57.3 | 54.1 | 55.4 | 63.1 | - | 2,946 | - | 4.1 |
| Zero-shot | 56.1 | 15 | 196x | 1.1 (3.7x) | |||||
Conclusion
We propose LongLLMLingua to address the three challenges, i.e., higher computational cost, performance reduction, and position bias for LLMs in long context scenarios. We develop LongLLMLingua from the perspective of efficient prompt compression, thus reducing computational cost. We further design four components, i.e., a questionaware coarse-to-fine compression method, a document reordering mechanism, dynamic compression ratios, and a subsequence recovery strategy to improve LLMs’ perception of the key information, with which LongLLMLingua demonstrate superior performance. Experiments on the multidocument QA, multi-hop QA, and long context benchmarks demonstrate that LongLLMLingua compressed prompt can derive higher performance than original prompts while both API costs for inference and the end-to-end system latency are largely reduced.
BibTeX
If you find this repo helpful, please cite the following papers:
@inproceedings{jiang-etal-2024-longllmlingua,
title = "{L}ong{LLML}ingua: Accelerating and Enhancing {LLM}s in Long Context Scenarios via Prompt Compression",
author = "Huiqiang Jiang and Qianhui Wu and and Xufang Luo and Dongsheng Li and Chin-Yew Lin and Yuqing Yang and Lili Qiu",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.91",
pages = "1658--1677",
}